Building an FHE compiler for the real world


The first step in bringing fully homomorphic encryption (FHE) to the masses involves making FHE both fast and usable for developers! Developers will then be empowered to bring privacy to whatever application they're creating.
We've been working hard the past months trying to solve this problem. Let's take a deep dive into what we've completed so far.
For this article, we'll assume you're already familiar with FHE at a high level. If not, we recommend starting with our intro article first. If you watched our talk at ZK Summit, this article shares a lot of the same information.
Wait, I thought FHE was too slow for anything practical...
Yes and no.
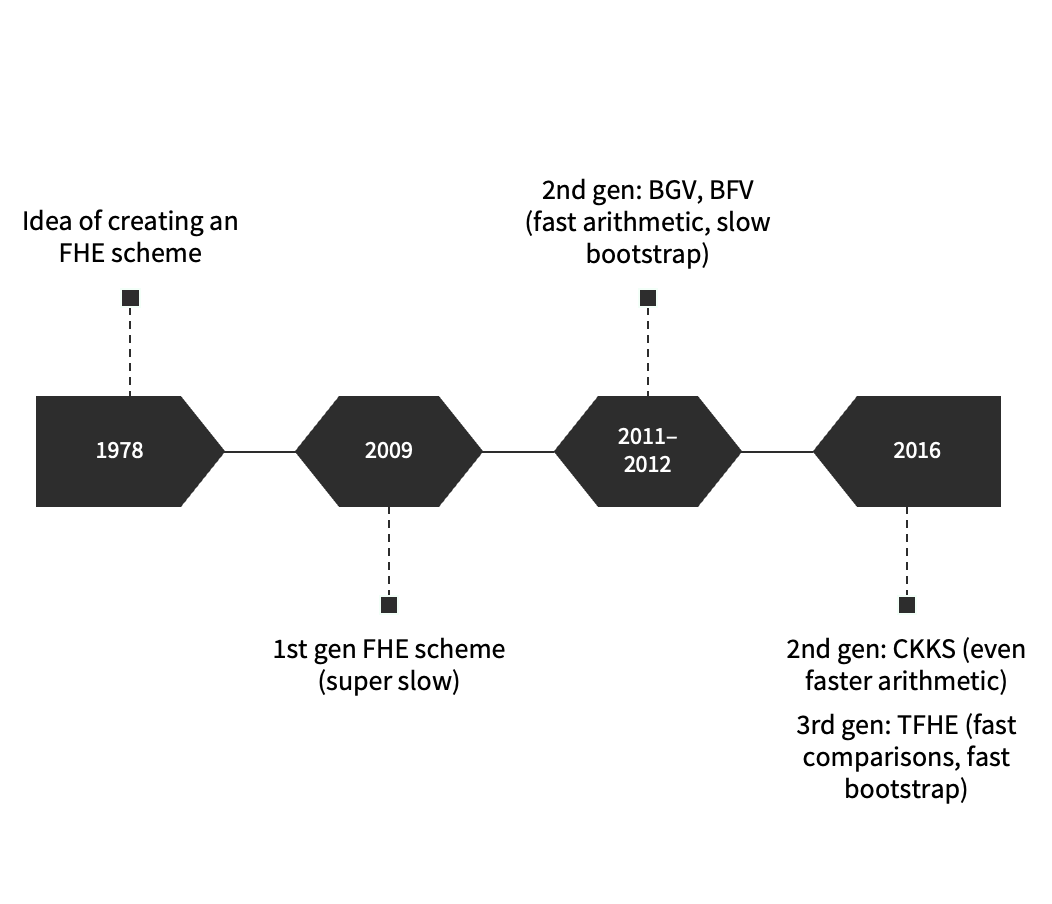
With the very first FHE scheme, it took on the order of minutes to multiply two encrypted numbers together.
Since the first scheme was constructed over 10 years ago, FHE has come a long way–what used to take minutes is now down to milliseconds on a MacBook Pro.
It is true that FHE can be slow for certain kinds of computations on certain kinds of data (especially if we're looking at machine learning applications). The bigger issue is that FHE will always be slow if you don't really know what you're doing. To get good performance out of FHE, you need to choose the best FHE scheme for your use case; furthermore, you need to know how to select the scheme parameters exactly right for your particular computation. The same computation may be 10-100x slower if you choose parameters that are larger than necessary; the same computation may also be 100-1000x slower if you choose an FHE scheme poorly suited to the kind of computation you want to do.
Picking an FHE scheme
The first step in integrating FHE into your application is to figure out which FHE scheme to use. There are 3 major scheme choices–BFV, CKKS, and TFHE+.[1]
We won't go into all the details of these FHE schemes but we've summarized their tradeoffs below.
For web3, many applications deal with financial data so we need exact computation (making the CKKS scheme, which supports approximate arithmetic, a poor candidate).
| BFV | TFHE+ | |
|---|---|---|
| + Fast arithmetic | + Fast comparisons | |
| + High precision | + Fast bootstrap (done with every op) | |
| + "Small" keys | - Slow multiply | |
| - Comparisons difficult[2] | - Precision/correctness issues | |
| - Slow bootstrap[3] | - Large keys |
Depending on the particular application, either BFV or TFHE+ could make sense. For applications requiring multiplication on encrypted data, BFV might be the best option. Alternatively, for applications that make extensive use of comparisons over encrypted data, TFHE+ might be best.
Of the two FHE schemes that seem most suitable for web3, you can see for yourself how different the performance is when performing 32-bit computation on a Macbook M1. In benchmarking these two schemes, we've used SEAL (version 4.1.1) for BFV and tfhe-rs (version 0.2.4) for the TFHE scheme with programmable bootstrapping.
| 32-bit integers | BFV (n = 4096) | TFHE+ |
|---|---|---|
| KeyGen | 0.0045 s | 10.6 s |
| Encrypt[4] | 0.0024 s | 1.1 s |
| Decrypt | 385 μs | 19 μs |
| Add | 15 μs | 34 μs |
| Multiply | 0.0043 s | 3.9 s |
| Compare | ??? | 0.15 s |
You'll notice a difference too in terms of key and ciphertext sizes between the two schemes. When it comes to using FHE on a blockchain, having large public keys for users presents a challenge as validators would have to download these public keys for each user.
| 32-bit integers | BFV (n=4096) | TFHE+ |
|---|---|---|
| Public key | ~205 KB[5] | ~110.6 MB[6] |
| Ciphertext | ~31 KB | ~ 263 KB |
For say 100 users, validators would have to keep track of (205 * 100) KB worth of public key data if the BFV scheme is used. For TFHE+, validators would have to keep track of (110.6 * 100) MB worth of public key data!
We use TFHE+ to refer to the newer variant of the TFHE scheme with programmable bootstrapping. ↩︎
As BFV uses arithmetic circuits, it can be quite difficult to implement comparisons on encrypted values. ↩︎
Bootstrapping is used sparingly if at all with this scheme. Generally, you set up the scheme to support a pre-determined amount of computations. ↩︎
Encryption using the public key. Neither version is parallelized (which could especially benefit TFHE's current encryption times). ↩︎
Compact version. Non-compact version is ~410 KB. Does not include Galois key (used if you want to "vectorize" the computation). ↩︎
The bootstrapping key is included in this number as it is needed to perform computations over the encrypted data. It's roughly 109 MB in size. ↩︎
Why is FHE so darn hard?
To work effectively with FHE (i.e. not have terrible performance and giant ciphertexts), you need to know quite a bit about lattice-based cryptography and abstract algebra.
Changing the value of one scheme parameter can have dramatic effects on possible values of other scheme parameters; in exchange for supporting more complex computations on encrypted data, you'll have bigger ciphertexts and public keys. There are also weird FHE-specific operations you've probably never heard of before such as relinearization, modulus switching, and bootstrapping. Additionally, you'll need to be comfortable working with arithmetic or binary circuits. One of the most important considerations for FHE schemes modeling computation as arithmetic circuits is how many sequential multiplications you want to do on encrypted data. For FHE schemes using binary circuits, implementing even simple operations like integer multiplication in an efficient manner can be quite involved (e.g. Karatsuba multiplication).
Regardless of which FHE scheme you select, you also need to figure out how to translate from numbers into polynomials (since that's the language of FHE). There are different ways to "encode" numbers into polynomials, each having its own tradeoff.
Here's an example of how changing the polynomial degree n can have a huge impact on performance for the BFV scheme.
| BFV scheme | n = 4096 | n = 8192 | n = 16384 |
|---|---|---|---|
| KeyGen | 4.5 ms | 22.7 ms | 72.5 ms |
| Encrypt | 2.3 ms | 5.6 ms | 15.9 ms |
| Decrypt | 0.39 ms | 1.5 ms | 5.8 ms |
| Add | 15 μs | 56 μs | 228 μs |
| Multiply | 4.3 ms | 17.4 ms | 108.3 ms |
Alternatively, you can see for the TFHE+ scheme how supporting higher precision has quite the effect on performance.
| TFHE+ scheme | 16-bit | 32-bit | 64-bit |
|---|---|---|---|
| KeyGen | 10.2 s | 10.6 s | 10.7 s |
| Encrypt | 0.69 s | 1.1 s | 1.8 s |
| Decrypt | 9 μs | 19 μs | 406 μs |
| Add | 12 μs | 34 μs | 136 μs |
| Multiply | 1 s | 3.9 s | 15 s |
| Compare | 0.09 s | 0.15 s | 0.25 s |
You may wonder what precision (the axis along which TFHE+'s performance is measured) has to do with polynomial degree (the axis along which BFV's performance is measured). Even the smallest degree n = 2048 supports 64+ bit computation in BFV! In terms of functionality, what n impacts is how many sequential multiplications you can do on encrypted data (before needing to bootstrap or decrypt and freshly re-encrypt). Thus, it's difficult to even do an apples-to-apples comparison between these two FHE schemes since their performance is impacted by different factors.
Making FHE usable
So how do we make FHE more usable for a normal engineer who isn't a cryptography expert?
High level idea: What if we could turn a "regular" program (say a C++, Python, or Rust program) into an FHE equivalent that operates on encrypted data?
Thus begins a new line of (mostly academic) work trying to make FHE usable for developers via an FHE compiler.
Sunscreen & FHE compiler efforts thus far
FHE compilers started as (and still are) mostly an academic/research effort. The first few FHE compilers provided only partial automation of parameter selection so the developer still needed to have quite a bit of expertise in the underlying cryptography. While compilers inevitably introduce a slowdown, most of them introduce a very significant slowdown (over 1000x vs. working directly with a low-level FHE library and hand coding the program). Naturally, as an academic effort, less thought goes into API design and whether the compiler is easy for developers to actually use.
Essential features you'd expect to find for real world applications are often missing as well. For data analytics applications, it's easy to imagine use cases where a third party company might want to run different computations on the same encrypted user data set. For blockchain related applications, it's common to feed the outputs of one program as the inputs to another. As they were created by cryptographers for cryptographers, previous compilers do not support such features.
At Sunscreen, we're building a compiler that makes FHE both fast and accessible. Compilers naturally introduce some overhead; however, we've tried to keep the overhead to about 10-100x. You, as the developer, share your Rust program with us. Behind the scenes, we figure out how to transform your good old Rust program into its FHE equivalent with input/output privacy.
Why Rust, you might ask? In addition to having a powerful and expressive type system, it's highly performant (like C/C++) and safe by design (unlike C/C++)!
We've benchmarked Sunscreen's compiler against existing FHE compilers that support exact computation; you can check out the results below. We run a chi-squared test according to the criteria set out in this SoK paper on FHE compilers. Time includes key generation + encryption + (homomorphic) computation + decryption. Experiments were performed on an Intel Xeon @ 3.00 GHz with 8 cores and 16 GB RAM.
| Compiler | Time (seconds) |
|---|---|
| Hand-coded in SEAL (no compiler) | 0.053 |
| Sunscreen | 0.072 |
| Microsoft EVA | 0.328 |
| Concrete | 977.1 |
| Google's Transpiler | 124.9 |
| Cingulata-BFV | 492.109 |
| Cingulata-TFHE | 62.118 |
| E3-BFV | 11.319 |
| E3-TFHE | 1934.663 |
If you want to check out the source code and run our Sunscreen benchmark yourself, feel free to look here!
Currently, our FHE compiler is mainly targeted towards web3 applications which have their own set of requirements and concerns.
What makes web3 different?
(1) Performance matters–with fast encryption times and arithmetic as major priorities. Additionally, we would prefer an FHE scheme with relatively small public keys and ciphertexts since storage on blockchain is quite expensive.
(2) We likely want to support computation with a high degree of precision (32, 64 bit computation) without incurring a huge performance overhead.
(3) Since we're working in a trustless setting, we need compatibility with efficient zero knowledge proof systems so that users can prove things on their encrypted values. Unfortunately, proving you have a well-formed FHE ciphertext is often very expensive (even with state-of-the-art proof systems). In practice, we'll need a zero knowledge proof compiler that integrates well with the FHE compiler.
Design and usability
Let's take a closer look at some of the design decisions we've made in building out our FHE compiler and how we've addressed web3-related challenges.
We've designed our compiler to be flexible so that we can swap out the backend FHE scheme (BFV) for another FHE scheme if desired. We imagine use cases where an engineer may want to work with the BFV scheme for building certain kinds of applications but a different scheme for other use cases.
Currently, the BFV scheme offers some of the best performance out of the box for arithmetic operations when looking at 32 and 64 bit computation (no hardware accelerators required!). Experience tells us that one of the most challenging aspects of working with FHE is getting parameter selection right so we've focused on automating parameter and key selection to make set up painless for developers. Additionally, data encoding is done automatically. Further along in the FHE lifecycle, our compiler automatically handles annoying FHE-specific efficiency-related operations for you, sets up the circuits, and parallelizes the program if possible.
From a usability angle, we've made it possible to run computations without FHE which can be useful for debugging. We also offer support for serialization (hello real life!) and WASM. But who wants to download and install a library when they're just trying to play around with the tech? That's why we've created a playground for developers to try out our compiler! You can also run the code examples from our documentation directly in browser by hitting the play icon ▶️.
What's next for us
While we don't want to spoil the surprise, we're working on more than just FHE.
In the coming months, we'll share details on our work on zero knowledge proofs.
If you'd like to keep up with our progress, follow us on Twitter or join our Discord. Finally, if you want to contribute to our efforts in the space, feel free to reach out to us at hello@sunscreen.tech (we're hiring engineers and still running our grants program!).