Private Lookups: The Trojan Horse of Homomorphic Encryption


We often get asked if homomorphic encryption is used at scale today (i.e. deployed to hundreds of millions of users). The answer is yes, primarily thanks to private information retrieval!
If you have an iPhone, each time you get a call today you’re using private information retrieval (PIR) under the hood to look up information about the caller id without revealing to the server who’s calling you. Additionally, if you happen to use Facebook’s end-to-end encrypted Messenger app, you’re using PIR each time you click a link in your chat. These links are checked against known malicious links in a way that doesn’t compromise the user’s privacy. There are in fact more wide scale deployments of PIR but these are some of the more interesting consumer-facing ones.
If you’re familiar with Ethereum’s privacy roadmap, PIR fits most cleanly into the bucket of “private reads,” enabling users to query or browse Ethereum apps without worry of surveillance from say their RPC provider. You can learn more about the effort to bring private reads to Ethereum here.
In this blog post, we'll be providing an overview of PIR, along with a demo on how we can bring privacy to DNS so that you can privately look up websites. We chose DNS as it's something many people are familiar with and a good introductory medium with which to showcase PIR. If you'd like to jump straight to our demo, you can check it out here.
So what is private information retrieval and what does it have to do with homomorphic encryption?
Developing intuition for PIR
Private information retrieval (PIR for short) can be thought of as a way to privately read some information from a database. Specifically, PIR enables a user (often referred to as the "client") to retrieve an item from a database without the database owner (the "server") knowing which item was retrieved! Many PIR constructions rely on homomorphic encryption, not to be confused with fully homomorphic encryption (FHE) which is more than a decade younger than PIR.
The strawman construction of a PIR scheme simply involves the server sending the entire database back to the user. While this construction achieves our privacy goal of the server not learning which item the user wants to look up, it is obviously unsatisfactory. Thus, one goal of PIR is to minimize the data that has to be shared between the user and server (in technical speak, reduce communication). Another major goal is to reduce the amount of work the server has to do in providing an answer to the user; this is what most of the research work is focused on today (reduce computation). Homomorphic encryption enables computation directly over encrypted data and will ultimately help in reducing the amount of communication between the client and server.
PIR constructions fall into two camps: those that are “single server” and those that are “multi-server.” Multi-server PIR looks more like MPC in that to obtain privacy you must assume the servers do not collude with one another. In this article, we’ll be looking at single-server PIR which often relies on lattice-based cryptography (which forms the the foundation of FHE as well).
A brief math detour
We'll put the encryption part aside for now and look at how we can use matrix-vector multiplication to just perform an array lookup on a database.
Doing lookups in the clear
Suppose we have a database containing the values \([16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1]\). We can pack these into the following matrix:
\[ D=\begin{bmatrix} 16 & 15 & 14 & 13 \\ 12 & 11 & 10 & 9 \\ 8 & 7 & 6 & 5 \\ 4 & 3 & 2 & 1 \\ \end{bmatrix} \]
To make a query against the server, the client must compute the row \(r\) and column \(c\) indices from \(i\) where
\[r = i / 4\]
\[c = i\ \mathrm{mod}\ 4\]
Suppose the client wants to retrieve the item at index \(i=6\). This gives \(r=1\) and \(c=2\).
The client constructs a vector with zeros everywhere except in the \(c=2\) row where they place a 1:
\[ q=\begin{bmatrix} 0 \\ 0 \\ 1 \\ 0 \\ \end{bmatrix}\]
Now, the server can compute:
\[ y=Dq= \begin{bmatrix} 16 & 15 & 14 & 13 \\ 12 & 11 & 10 & 9 \\ 8 & 7 & 6 & 5 \\ 4 & 3 & 2 & 1 \\ \end{bmatrix}\begin{bmatrix} 0 \\ 0 \\ 1 \\ 0 \\ \end{bmatrix} =\begin{bmatrix} 14 \\ 10 \\ 6 \\ 2 \\ \end{bmatrix} \]
and send \(y\) back to the user. The user can then locally extract the element \( r=1\) , which is 10, the value at index 6.
Obviously this construction provides little privacy for the user since the server can see the user's request and deduce the user is interested in the value at index 6.
Encrypting the client's request
So how will we augment the prior construction to hide the user's request from the server?
At the heart of many PIR schemes lies some form of homomorphic encryption, meaning an encryption scheme supporting computation directly over encrypted data (ciphertexts). Suppose we have an encryption scheme that supports the following operations over messages \(m_a\) and \(m_b\):
- Multiplication by a plaintext scalar \(b\): \(\mathrm{Enc}(m_a * b) = b * \mathrm{Enc}(m_a)\)
- Addition of ciphertexts: \(\mathrm{Enc}(m_a + m_b) = \mathrm{Enc}(m_a) + \mathrm{Enc}(m_b)\)
Now that we know what a linearly homomorphic encryption scheme is, let's see how the user can privately lookup items in a database. Instead of sending a vector with plaintext data, the user now sends over the following vector where all the values are encrypted under a key they own:
\[ q=\begin{bmatrix} Enc(0) \\ Enc(0) \\ Enc(1) \\ Enc(0) \\ \end{bmatrix} \]
Since the encryption scheme is linearly homomorphic, the server can directly compute the following:
\[y=Dq=\begin{bmatrix} 16 & 15 & 14 & 13 \\ 12 & 11 & 10 & 9 \\ 8 & 7 & 6 & 5 \\ 4 & 3 & 2 & 1 \\ \end{bmatrix}\begin{bmatrix} Enc(0) \\ Enc(0) \\ Enc(1) \\ Enc(0) \\ \end{bmatrix} \]
The user receives the following result from the server:
\[ y=\begin{bmatrix} Enc(14) \\ Enc(10) \\ Enc(6) \\ Enc(2) \\ \end{bmatrix} \]
and can decrypt it using their private key to get back
\[ \begin{bmatrix} 14 \\ 10 \\ 6 \\ 2 \\ \end{bmatrix} \]
This solution at least reduces the communication; instead of returning the full \(NxN\) matrix to the user, the server sends back a single column. Modern constructions are a lot more interesting than what we've shown but hopefully our brief walkthrough provides some intuition for how homomorphic encryption enables private database lookups.
Toolbox for modern PIR constructions
If you're more mathematically inclined, you won't be surprised to learn that many single-server PIR constructions rely on lattice-based cryptography which nicely supports matrix-vector multiplication as we saw above.
Intuitively, it seems like if the server truly doesn't learn what item the user is interested in, then the server must necessarily "touch" every item in the database. Such a setup is prohibitively expensive. Indeed, in the simple construction above, the server touched every element in the database matrix when performing the matrix-vector multiplication. One option to address this is batching many different user queries together when doing a single linear scan over the database so that the amortized cost per query is lower.
To provide better efficiency, a lot more machinery is involved in modern day constructions. Intuitively, there are a few levers researchers can pull on-communication, security, and correctness. Specifically, we can reduce the amount of computation that needs to be done by the server (thereby improving response times) if we're okay with the user or server performing some "pre-processing" or if we don't mind introducing some additional commmunication between the two parties. Another trick is to relax security/privacy, meaning the server learns that the user is interested in say one of the first 100 items in a database with 1000 total entries. Finally, researchers can relax correctness, meaning there may be a non-neglible probability that the client does not get back the item they were looking for; however, the client will know that they received the wrong item so they can submit another private query.
Finally, PIR constructions often assume the user provides the server with the relevant index, meaning the user must know the item's location in the database. This seems impractical for many applications but there is a way around this using probabilistic filters to obtain keyword search.
Augmenting DNS to provide private lookups
Now that we've covered PIR, let's look at how to provide private lookups in the context of DNS.
DNS and HTTPS 101
Before diving into our demo, we'll provide a brief rundown of DNS and the privacy it does and does not provide today. Feel free to skip this section if you're familiar with DNS.
Suppose you want to check out the latest happenings in FHE, so you open up your web browser, type blog.sunscreen.tech into your address bar and hit enter. Let's take a look under the hood to see how this actually works via Domain Name System (DNS).
Akin to how phone numbers direct your call to Alice's phone and not Bob's, an Internet Protocol (IP) address allows the network to direct your request to Sunscreen and not Youtube. Unfortunately, just as remembering your friends' phone numbers is hard, it's also hard to remember which IP address goes with which service. The Domain Name System (DNS) was introduced in 1983 to solve this problem. Think of DNS like an old school phone book; you can give it the name of a service (blog.sunscreen.tech) and it will give you the IP address (i.e. "number"). When you type in a URL and hit enter in your browser it actually makes 2 network requests: the first is a DNS lookup to convert the name into a number and the second is to actually fetch the blog.
When we run the nslookup command (to manually perform a DNS request) in our computer's terminal for sunscreen.tech, it responds that there are 4 IP addresses corresponding to sunscreen.tech: 143.204.160.48, 143.204.160.16, 143.204.160.54, and 143.204.160.53.
Security
Unfortunately, DNS as originally designed has a few privacy and security problems:
- Due to the lack of encryption, passive observers can see what host your browser is requesting.
- The DNS server operator knows which host you're looking up.
- Even worse, DNS lacks message authentication, allowing active adversaries to modify either the DNS request or response. This allows the adversary to trick your browser into sending the request to a malicious host.
While the first two issues aren't ideal, the third is extremely dangerous given the distributed nature of the internet. To address this, DNSSEC was developed in the mid 1990s to provide cryptographic authentication to ensure your lookup isn't tampered with. However, passive network observers can still see what address you're looking up and easily track your browsing behavior. With DNS over HTTPS, we additionally get encryption, which hides the request and response from prying third party eyes.
However, the DNS server itself can still see the user's request. Is this as good as we can hope to do? Intuitively, it feels like the server must be able to view the user's query in order to process a response.
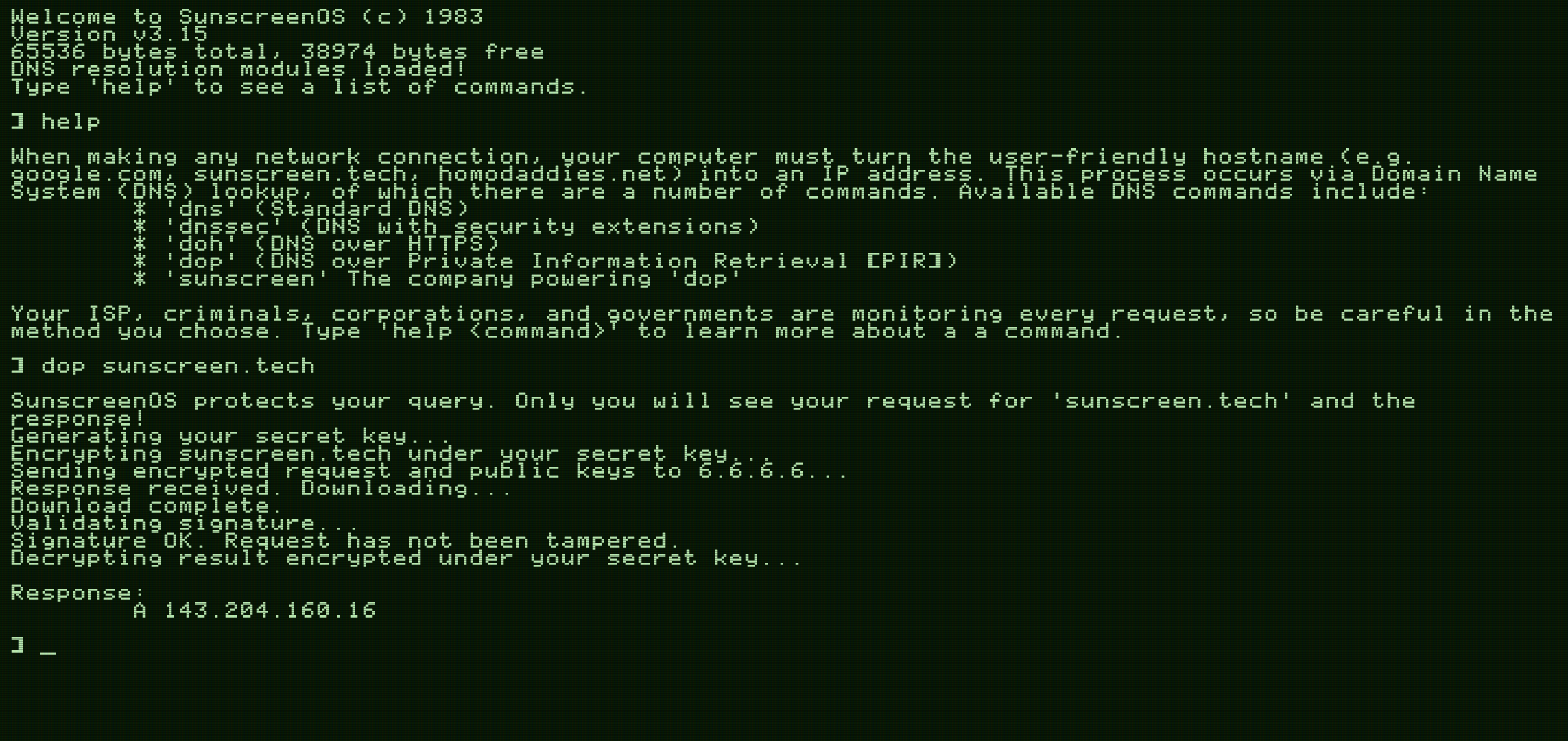
Our demo
As it turns out, we can additionally hide the request from even the DNS server itself using PIR.
We'll be using FrodoPIR, a 2023 PIR scheme that relies on lattices from the Brave team. What's great about this construction is that it's inexpensive to deploy/run in practice and it requires little computation done by the end-user. Unfortunately, it blows up the database size by ~3x but for our purposes this won't be much of an issue since the database is relatively small to begin with.
How does this work at a high level?
- Preprocessing: First, the server converts and "compresses" the database into a matrix (a fancier version of the \(D\) above). The database here consists of various websites (e.g.
sunscreen.tech) along with their IP address. The client downloads this compressed matrix along with some additional info and uses that to perform some preprocessing for future queries (allowing them to save time later!). - Send encrypted request: Next, the client creates an encrypted query vector with an indicator value for the corresponding entry in their vector (similar to the \(q\) vector in the simple construction above) and sends this vector over to the server.
- Server lookup: The server then performs the database lookup using the encrypted query vector and returns an encrypted result to the client. Roughly speaking, this is similar to the matrix-vector multiplication of \(Dq\) above to get the encrypted vector result \(y\).
- Receive result: Finally, the client uses their private key to decrypt and get the result (the website they wanted)!
Challenges
Unfortunately, things aren't entirely straightforward.
- Standard PIR schemes (like FrodoPIR) require the client knowing the location of the entry in the database. To get around this problem, we'll use ChalametPIR which provides a nice way to convert FrodoPIR (specifically PIR schemes relying on the Learning With Errors problem) into a scheme supporting keyword search. This is achieved via binary fuse filters, generally a faster and more memory efficient alternative to bloom filters.
- What happens if client looks up an entry (i.e. website) that doesn't exist? To avoid sending random garbage back to the user, we get around this by checksumming the value entry and returning an invalid checksum with overwhelming probability if the entry isn't in the database.
Our demo putting all these concepts together is available here. You can lookup various websites, trying out old school DNS, DNSSEC, DNS over HTTPS, and then finally our DNS using PIR.
So can I integrate PIR into my app today?!
Potentially. If you're primarily interested in point lookups and have a relatively small database (say <100GB) that you're okay updating say once or twice a day, then yes.
However, depending on what kind of data is in the database and what sort of lookups you want to offer, there may be some complexity in reformatting the database to support PIR. The most straightforward query to support today is point lookups. If you're hoping to support some sort of SQL, graph, or vector database, there will be a number of challenges to bring PIR to your app.
Additionally, you'll want to consider how large the database is and how often the database needs to be updated. Single-server PIR (what we looked at here) tends to have some performance issues beyond databases of a few hundred GB. If you'd like to work with larger databases, it's worth exploring multi-server PIR schemes. Furthermore, PIR can be tricky to work with if you need the database to be updated in real time. You may already have a sense for why database updates are problematic based on the preprocessing step above. Pre-processing usually depends on the contents of the database and would thus need to be repeated any time the database changes.
Finally, if you're worked with FHE before, you may know that adding privacy to the computation slows things down. We'll run into a similar issue with PIR so you'll have to take into account if your use case can support a bit more added latency. Many of the real-world deployments of PIR (e.g. Apple, Meta) are highly customized to get good performance.
Parting thoughts
To bring meaningful privacy to the web, we need PIR, often in conjunction with other advanced cryptography.
Although we've focused on consumer use cases in this blog, we think much more value can be unlocked by bringing PIR to B2B applications, starting with the crypto and fintech space. Some of the most exciting use cases we've explored are enabling government customers to privately lookup individual transaction history data on blockchain analytics platforms, as well as enabling crypto exchanges (or more generally fintechs) to cross-query other platforms to identify bad actors.
If you're more technically inclined and want to continue learning about PIR, we highly recommend this video. As always, feel free to reach out with any questions or feedback.