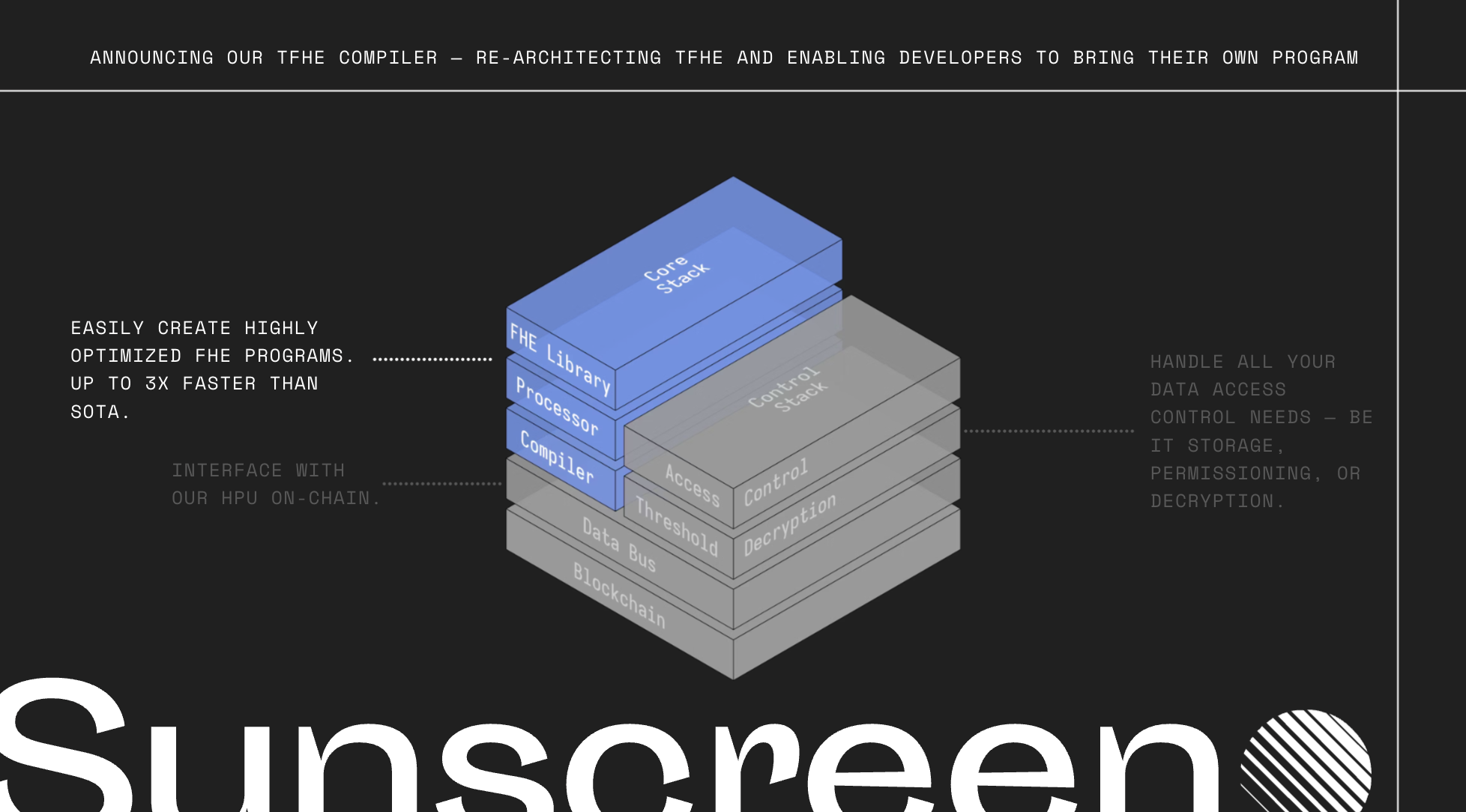
A new vision for TFHE and compilers
We re-imagine how computing should be done in FHE using a novel computing paradigm and develop a new FHE compiler design to realize the vision in which developers "bring their own program." Our 2nd gen compiler forms the foundation of our new vision, the "secure processing frameowrk."

Fully homomorphic encryption (FHE) enables running arbitrary computer programs over encrypted data, allowing users to protect their data while still allowing that encrypted data to be used in an application. With FHE, we can enable apps like fully customizable AI agents--trained on any data, no matter how sensitive--or hidden trading strategies in an on-chain ecosystem.
Existing tools for FHE are not built in a way that allows developers to easily create privacy preserving applications. Furthermore, their underlying approaches to homomorphic computing (i.e. computing over the encrypted data) are not architected in a way that will scale well as hardware evolves.
The inspiration for our latest work comes from asking ourselves two fundamental questions:
- How do we truly scale a technology?
- How do we effectively onboard developers to a new technology?
In answering these questions, we (1) re-imagine how computing should be done in FHE using a novel computing paradigm and (2) develop a new FHE compiler design to realize the vision in which developers "bring their own program," rather than re-write their existing application to leverage FHE.
We focus on the Torus FHE (TFHE) scheme, a particular FHE scheme that supports a variety of operations over encrypted data as well as unlimited computation. These features make TFHE especially well-suited to blockchain where it's unknown at setup time how many computations or what kind of computations the developer would like to perform (e.g. this is akin to how Vitalik/EF doesn't know all possible applications that developers might try to build on Ethereum).
Unlike existing approaches to TFHE, our new paradigm combines a special form of bootstrapping, known as "circuit bootstrapping," with multiplexers to realize arbitrary computation in a way that scales well with hardware. By building a virtual processor customized for FHE operations and integrating it as backend to the LLVM toolchain, we enable developers to write their program directly in a mainstream language today.
Re-architecting (T)FHE
Many people (experts included) take a potentially misguided approach to evaluating FHE schemes, focusing on the performance of individual operations rather than entire programs. As a simple thought experiment, consider the following: In System A, each operation takes 1 second. In System B, each operation takes 2 seconds. To instantiate program P with System A, we will need 3 operations but these must be done sequentially. With System B, we also need 3 operations but these can be done all in parallel. Would you prefer to use System A or B for the program?
A visual for those of you that don't want to do the math.
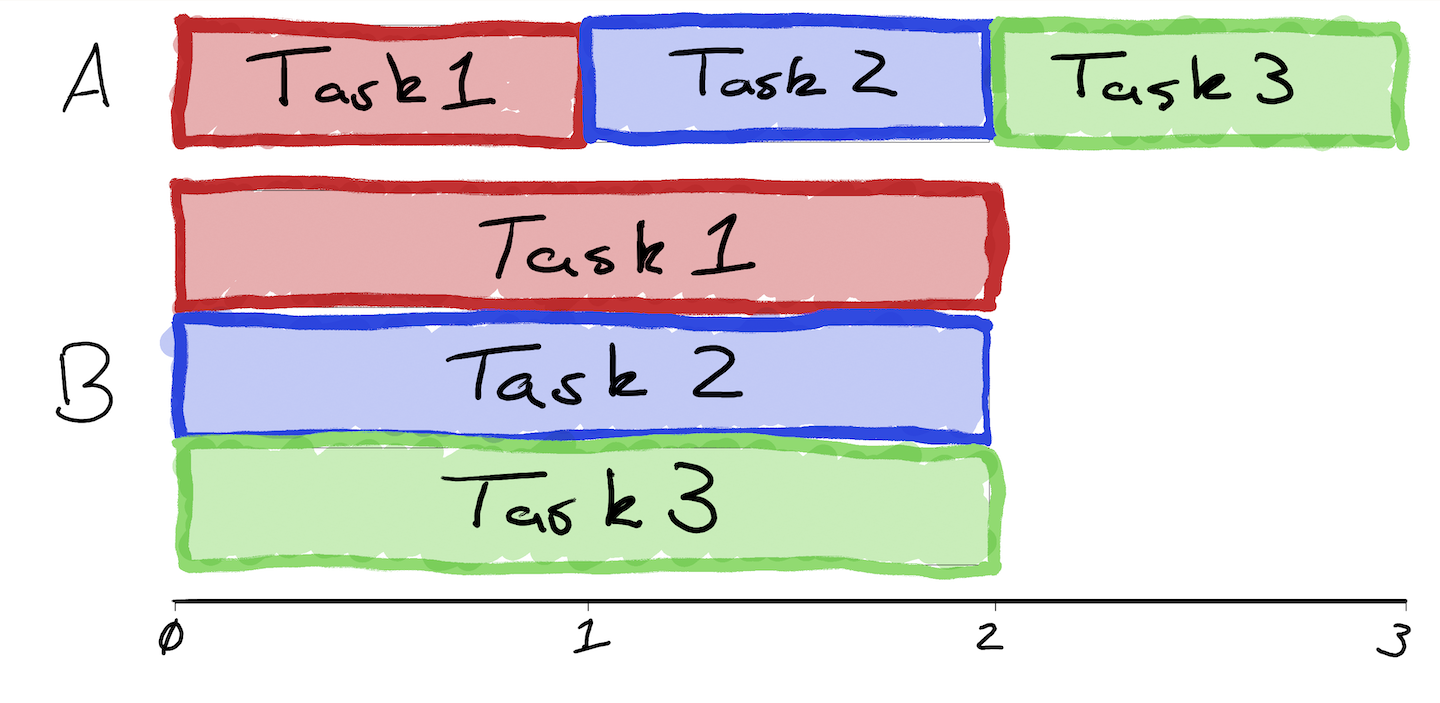
We take a long term view on FHE. For FHE to scale over the coming years, it must be architected to best suit hardware (be it cores, GPUs, or eventually ASICs), rather than expecting hardware to somehow magically accelerate FHE. Specifically, this means designing the homomorphic computing paradigm to maximize parallelism and reduce the critical path in the circuits themselves. Roughly speaking, maximizing parallelism enables us to increase throughput, which is key to unlocking performance with dedicated accelerators. By reducing the critical path, we can obtain lower latency.
In looking at the landscape today, we found that existing TFHE-based approaches do not prioritize these goals.
A brief history on TFHE and bootstrapping
Regardless of which FHE scheme you choose to work with today, a major challenge is "noise." We won't go into exactly what this is but it suffices to say noise is a bad thing. In working with FHE, we need to make sure that the noise doesn't grow so large that we will no longer be able to successfully decrypt the message.
To reduce the noise in a ciphertext so that we can keep computing over it, a special operation called bootstrapping is needed. Bootstrapping is key to performing unlimited computation so a lot of research effort has gone into figuring out how to make this operation fast.
There are various FHE schemes out there such as BFV (which our old compiler was based on), CKKS, and TFHE. The "T" in TFHE stands for torus and this scheme is sometimes referred to as CGGI16 after its authors and the year in which it was published. The former two schemes are generally used in "leveled" format, meaning we only evaluate circuits up to a certain depth, which severely restricts the applications developers can build.
What's great about TFHE is that it made bootstrapping and comparisons relatively cheap (i.e. fast) compared to other FHE schemes. There are some drawbacks to this scheme; most notably, arithmetic is usually more expensive using TFHE than with BFV or CKKS. Additionally, there's a fairly noticeable performance hit when upping the precision (i.e. bit width) in TFHE.
It turns out that there are actually a few bootstrapping varieties for TFHE; namely, we have gate bootstrapping (the OG way), functional/programmable bootstrapping, and circuit bootstrapping.
Gate bootstrapping is what most TFHE libraries and compilers rely upon. It's a technique designed to reduce the noise in a ciphertext and comes from the original TFHE paper.
Functional (sometimes known as programmable) bootstrapping can be viewed as a generalization of gate bootstrapping in that it (1) reduces the noise in a ciphertext and (2) performs a computation over the ciphertext at the same time. At first glance, this approach seems to provide only benefits...after all, you're basically getting two operations for the price of one, right? Going back to our thought experiment, it turns out this approach behaves a lot like System A.
Circuit bootstrapping was introduced many years back but appears to be used thus far for either "leveled" computations or as an optimization when implementing certain forms of functional/programmable bootstrapping. Circuit bootstrapping, like gate bootstrapping, only reduces ciphertext noise. However, it has the nice property of having an output that's directly compatible with a (homomorphic) multiplexer...
Next, we'll look at our computing paradigm which makes use of circuit bootstrapping and homomorphic multiplexers.
Breaking down our approach: CBS-CMUX
We can realize arbitrary computation using multiplexers, independent of FHE. You can think of a multiplexer (known as a mux) as implementing an "if" condition; given two options d0 and d1 and a select bit b, we get d0 if b is 0 and d1 if b is 1. The FHE equivalent of a multiplexer is called a "cmux" as it operates over encrypted data to produce an encrypted output. This turns out to be interesting in the context of FHE.
Our high level goal is to perform general computation using a multiplexer tree before going on to reduce the noise (via the circuit bootstrap) so that we can continue performing more computations over the encrypted data. We must make sure we do not exceed the noise budget when doing the multiplexer tree, otherwise we're in a lot of trouble since we may no longer be able to recover the data. While we won't get into the details, there's also a type mismatch between the cmux and circuit bootstrap which requires us to perform some additional FHE operations to get the output of the cmux into the "correct" format to feed back into the circuit bootstrap.
We call our computing approach the "CBS-CMUX approach" as the combination of these two operations allows us to realize arbitrary programs.
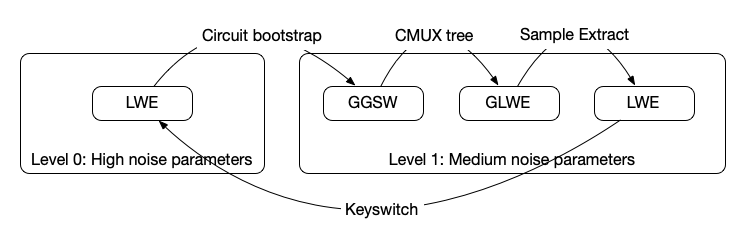
There are a few different ciphertext types (e.g. GGSW, GLWE) that we'll have to switch between but we won't discuss those here. While we won't dive into the details now, an upcoming technical paper will provide more insight on how all of this fits together.
While all of this may seem like a nightmare to an engineer, our compiler handles all of these tasks on your behalf automatically.
Our approach:
- Reduces the number of bootstrapping operations in the critical path: Specifically, for key operations like 16-bit homomorphic comparisons, our approach reduces the number of bootstraps in the critical path down to 1. This is important because bootstrapping is one of the most expensive operations in TFHE. When we instantiate a 16-bit homomorphic comparison using functional/programmable bootstrapping, there are 3 respective bootstrapping operations in the critical path. Even if we have specialized hardware, we would have to wait for each one of these functional bootstrapping operations to be done sequentially.
- Provides greater intra-circuit parallelism: When given access to sufficient cores/computing resources, we can speed things up significantly (like System B).
"BYO program"
Developers should be able to bring their own program, rather than having to rewrite their program in some eDSL or newly created language.
Accordingly, the developer experience today allows you to write your program directly in C or bring your existing C program (with some restrictions). To create an FHE program, you just need to add directives (i.e. simple syntax) indicating which functions are FHE programs and which inputs/outputs should be encrypted (i.e. hidden).
Parasol compiler today
Our compiler abstracts away the usual difficulties of working with FHE which includes selecting FHE scheme parameters, translating your program into an optimized circuit representation, and inserting in FHE-specific operations. Additionally, it's compatible with our single-key TFHE scheme variant (useful if your application operates over a single user or entity's data) as well as our threshold TFHE scheme variant (useful if your application operates over multiple entites data).
Parasol supports common operations like arithmetic, logical, comparison operations. We support imports, and functions can be inlined, making it easier to create modular programs with reusable pieces.
We started with C as a proof-of-concept. Depending on demand, we can add support for other LLVM-compatible frontends like Rust.
There are a number of features we plan to add soon such as signed integers, higher precision integers (today we only support up to 64 bits), division by plaintext, branching over plaintext values, and arrays.
Overview of our design
To provide a great developer experience, we built an LLVM-based compiler. The benefits of this approach are twofold. First, it allows developers to use a variety of mainstream programming languages like Rust, C, or C++ with the only changes to their programs being the directives mentioned above. Second, it allows us to leverage decades worth of optimizations and transformations that are already built into LLVM.
However, how do we efficiently run whatever is output from this compiler? The machine you and I are using won't be able to do this. Accordingly, we need to build a virtual processor that can actually run these FHE programs in an efficient manner.
An important goal of ours was to provide compact program representations. To achieve this, our processor expresses programs as high level operations (e.g. add, multiply, etc.) that it dynamically expands into FHE circuits at runtime.
Our processor, and thus compiler, rely on our in-house created variant of the TFHE scheme.
Technical teaser
For those who'd like to understand more about our stack, we provide some details below. Stay tuned for our upcoming research paper!
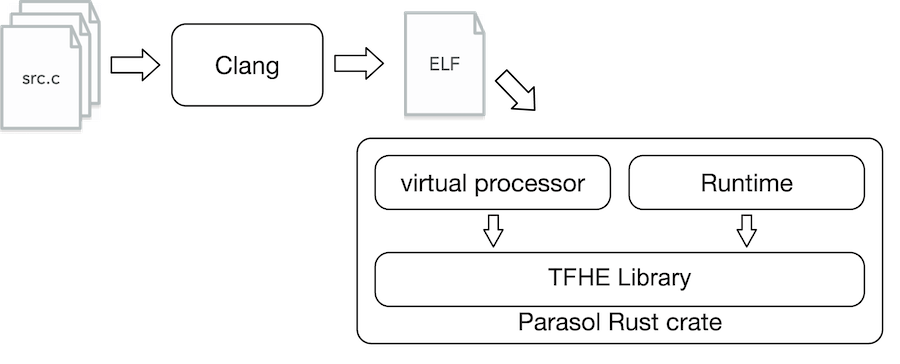
LLVM-based compiler: Developers write their FHE programs in C today and compile it using a version of clang that supports our virtual processor. Without the virtual processor, the generated FHE programs can't be run anywhere! Feel free to look here if you'd like to understand how to create an LLVM backend.
Virtual processor: Now to actually run the programs output by clang, we have our virtual processor. We adopt an out-of-order processor design and feature dynamic scheduling within instructions to maximize parallelism. We designed a custom instruction set architecture that enables running programs over a mix of plaintext and encrypted data. Doing so required re-imagining memory at the processor level, adding new instructions to support branching over encrypted data, and building our own circuit processor to support the CBS-CMUX computing approach.
TFHE library: At the lowest level of the stack is our optimized TFHE library which implements the cryptographic operations needed in the TFHE scheme. In theory, different TFHE libraries could be plugged in to work with our processor. However, given we're the only team implementing the CBS-CMUX approach, it made the most sense to have our own library.
The high level workflow is depicted below.
Show me some code!
So what does a program look like when using Parasol? We provide a simple example showing how to do a private transfer below.
#include <stdint.h>
[[clang::fhe_circuit]] void transfer(
[[clang::encrypted]] uint32_t *amount,
[[clang::encrypted]] uint32_t *balance
) {
uint32_t transfer_amount = *amount < *balance ? *amount : 0;
*balance = *balance - transfer_amount;
}
You'll notice that apart from [[clang::fhe_circuit]] and [[clang::encrypted]], this is just a regular C program.
While the benefits of our approach are more apparent in buidling large complex programs, we hope this gives you a taste of what the experience is like!
Benchmarks
We benchmark Parasol against existing FHE compilers (that support comparisons over encrypted data).
Based on the criteria set out in this SoK paper, we consider how compilers perform on a chi-squared test and a simple cardio application that computes a patient's risk of heart disease in the same manner as risk estimators provided by the American College of Cardiology. The former application is heavy on addition and multiplication operations whereas the latter is heavy on comparison operations.
Of the 5 compilers we consider, ours is the only one to rely on circuit bootstrapping as the primary bootstrapping method. Concrete relies on programmable (aka functional) bootstrapping whereas Google, E3, and Cingulata rely on the older gate bootstrapping approach.
Experiments were performed on an AWS c7a.16xlarge instance (64 vCPUs, 128GB RAM) and all compilers are set to provide 128 bits of security.
Transparently, our approach shines when sufficient cores are provided with which we can parallelize tasks across. You will see less of a performance benefit with our compiler/approach if the FHE computation is being carried out on a machine with relatively few cores (e.g. 16, 32 cores). Please note that this only applies to the computing party; there's no issue at all if the end-user, providing their encrypted data, uses a laptop or smartphone!
Chi squared benchmarks
We first look at how our compiler performs for the chi-squared test with respect to runtime of the generated FHE program, size of the compiler output, and memory usage.
Runtime includes circuit evaluation (e.g. not key generation, encryption of inputs). In considering program size, there are slightly different meanings depending on the compiler due to architectural differences. We list the size of Parasol’s emitted ELF program, Concrete’s MLIR representation, and Google transpiler’s binary circuit intermediate representation. For E3 and Cingulata, we give the size of the resulting native executable.
| Compiler | Runtime | Program size | Memory usage |
|---|---|---|---|
| Parasol | 610ms | 256B | 1.0GB |
| Concrete | 1.84s | 1.41kB | 1.82GB |
| Google Transpiler | 13.8s | 323kB | 299MB |
| E3-TFHE | 440s | 2.87MB | 182MB |
| Cingulata-TFHE | 85.6s | 579kB | 254MB |
You'll notice that Parasol consumes more memory than compilers based on gate bootstrapping (i.e. Google, E3, Cingulata); this is due in part to the larger circuit bootstrapping key.
Cardio benchmarks
We also consider how our compiler performs for the cardio program with respect to runtime of the generated FHE programs, size of the compiler output, and memory usage.
| Compiler | Runtime | Program size | Memory usage |
|---|---|---|---|
| Parasol | 920ms | 528B | 1.0GB |
| Concrete | 2.13s | 10.4kB | 4.0GB |
| Google Transpiler | 3.26s | 11.4kB | 274MB |
| E3-TFHE | 119s | 1.87MB | 181MB |
| Cingulata-TFHE | 2.98s | 613kB | 254MB |
What the future holds
The Parasol compiler forms the foundation of our new vision, the "secure processing framework." The SPF will allow one (FHE) program to be used on any chain, regardless of virtual machine.
We'll be open-sourcing Parasol in the next few weeks and providing comprehensive documentation to help get you started. We're excited to finally release work that's taken us many months to achieve! We'll be sharing more about the SPF and accompanying testnets soon. If you're interested in previewing these offerings, our team is happy to chat and learn about your unique needs.
Finally, if you're in Toronto this May for ZK Summit or Consensus, feel free to reach out to me personally if you'd like to say hi!